

Existen diversos programas de software disponibles para el reconocimiento de voz en entornos domésticos y profesionales.
En la actualidad, al contactar con grandes empresas, rara vez responde una persona. En su lugar, un sistema automatizado de voz te guía mediante menús, donde puedes decir palabras específicas en lugar de pulsar botones. Este avance se debe a programas de reconocimiento de voz, sistemas telefónicos automatizados de alta precisión.
El software de reconocimiento de voz también se usa en hogares y empresas para dictar textos en procesadores de palabras o correos electrónicos, e incluso para ejecutar comandos como abrir archivos o navegar menús. Hay soluciones especializadas para transcripciones médicas o legales.
Es especialmente útil para personas con discapacidades que limitan la escritura, como parálisis de manos o baja visión, permitiendo dictado y control por voz. Algunos sistemas almacenan patrones de habla para adaptarse a deterioros progresivos.
Los programas modernos se clasifican en dos categorías principales:
Vocabulario pequeño / muchos usuarios
Ideales para atención telefónica automatizada, manejan diversos acentos y patrones de habla, pero limitados a comandos básicos como números o opciones de menú.
Vocabulario amplio / usuarios limitados
Óptimos para empresas con pocos usuarios. Ofrecen precisión superior al 85% tras entrenamiento, con vocabularios de decenas de miles de palabras, pero su rendimiento cae con usuarios no entrenados.
Los sistemas antiguos distinguían entre habla discreta (palabras separadas por pausas) y continua (natural). Hoy, casi todos manejan habla continua de forma fluida.
De la voz a datos
 Un convertidor analógico-digital (ADC) transforma las ondas sonoras en datos digitales mediante muestreo preciso. Tasas altas mejoran la calidad.
Un convertidor analógico-digital (ADC) transforma las ondas sonoras en datos digitales mediante muestreo preciso. Tasas altas mejoran la calidad.Para convertir voz en texto o comandos, el proceso inicia con vibraciones aéreas captadas por un convertidor analógico-digital (ADC), que digitaliza el sonido mediante muestreo frecuente. Se filtra ruido, se separa por frecuencias (tonos), se normaliza volumen y se alinea temporalmente con plantillas almacenadas.
La señal se segmenta en fracciones de segundo, especialmente para consonantes oclusivas como 'p' o 't'. Estos segmentos se comparan con fonemas (unidades mínimas de sonido; ~40 en inglés, variables por idioma).

El desafío clave: analizar fonemas en contexto mediante modelos estadísticos complejos, comparándolos con bibliotecas de palabras y frases para inferir el mensaje probable.
Reconocimiento de voz y modelado estadístico
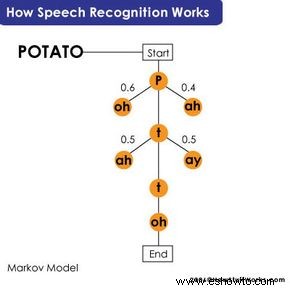
Sistemas tempranos usaban reglas gramaticales rígidas, fallando ante acentos, dialectos o habla continua. Hoy, modelos estadísticos como el modelo oculto de Markov y redes neuronales usan probabilidades para descifrar variaciones.
En el modelo de Markov, fonemas forman cadenas probabilísticas por palabra o frase. Ejemplo: 'reconocer el habla' vs. 'destrozar una bonita playa' se distingue por contexto y entrenamiento.
Con vocabularios de 60.000 palabras, las combinaciones son inmensas (216 billones para tres palabras). El entrenamiento con miles de horas de voz transcrita optimiza modelos acústicos y probabilísticos.
Usuarios finales entrenan el sistema en 10 minutos, adaptándolo a su voz y términos específicos (médicos, legales).
Debilidades y limitaciones del reconocimiento de voz
 Un micrófono con cancelación de ruido de alta calidad mejora drásticamente la precisión.
Un micrófono con cancelación de ruido de alta calidad mejora drásticamente la precisión.Ningún sistema es perfecto. Factores clave:
Baja relación señal/ruido: Ruido de fondo o tarjetas de sonido deficientes interfieren. Solución: entornos silenciosos, micrófonos cercanos y de calidad.
Habla superpuesta: Dificultad con conversaciones múltiples.
Alta demanda computacional: Requiere procesadores potentes; vocabularios ocupan mucho espacio. Mejora constante con hardware.
Homónimos: Palabras idénticas en sonido pero distintos significados (ej. 'allí' y 'hay'). Contexto mitiga errores.
El futuro del reconocimiento de voz
Desde experimentos de Alexander Graham Bell hasta hoy, avances en potencia computacional han democratizado la tecnología. Proyectos como GALE de DARPA buscan traducción instantánea con >90% precisión, manejando jerga, acentos y ruido.
Próximamente: comprensión semántica hacia IA conversacional. En 25 años, nuestras computadoras podrían no solo reconocer, sino entender y responder.